







This post was originally published on the
XLAB Steampunk blog.
In the past few months, AI systems have caused quite a stir on the web. We couldn’t wait to get our hands dirty and try to write Ansible Playbooks even faster, or at least learn something new. In this post, we’ll take a look at the new AI trends seen around the IT world and we’ll test how we can use AI to create playbooks.
Or as ChatGPT would say, “Welcome to the wonderful world of AI! It’s like the Wild West of technology, where the robots are the sheriffs, and the algorithms are the outlaws. In this post, we’ll be taming the AI beast and teaching it to do our bidding.”
As I’m a firm believer in getting an answer quickly, let’s get right to it.
Will AI take your jobs? No.
Is AI capable of creating production-ready Ansible Playbooks? No.
Is using AI to write playbooks faster than writing playbooks yourself? Well, not really.
Is AI useful for writing playbooks? Yes.
ChatGPT LinkedIn page
The fact is, AI tools are changing the way we write Ansible Playbooks. Are they at a point where they can be trusted to do all the work for us?
While AI can help you create playbooks, the current state of AI systems and their knowledge base for writing Ansible Playbooks is not sufficient for generating production-ready playbooks without manual rewriting. That doesn’t mean you shouldn’t leverage AI in your automation journey and use it to create playbooks. It can be really useful, if we know how to use it.
The biggest advantage of AI tools is that you don’t have to start writing playbooks from scratch. Use these tools to get started and get a playbook you can build on and improve with the help of tools that check the quality of generated playbooks and help you fix all issues that AI tools miss, such as Ansible Lint or Steampunk Spotter.
AI tools are a great way to start, and when used in combination with quality checking tools, you can get production-ready, high-quality playbooks in hours instead of days.
Let’s take a look how.
Taking ChatGPT for a spin
Among the numerous AI systems that have been introduced to the public in recent years, we have a clear winner in terms of popularity among programmers and technicians. ChatGPT is very powerful when it comes to generating human-like texts. It can be very useful in automating certain tasks such as generating content and answering questions, but not without limitations, especially when it comes to the complexity of the task or very specific questions about a certain topic.
Although using ChatGPT to generate playbooks seems to be a convenient solution, it is important to consider whether this method can generate high-quality playbooks that are ready for use in production environments. AI-generated playbooks may offer some level of automation, manual review and validation is still crucial to ensure their reliability and security.
Even ChatGPT agrees and warns you in advance:
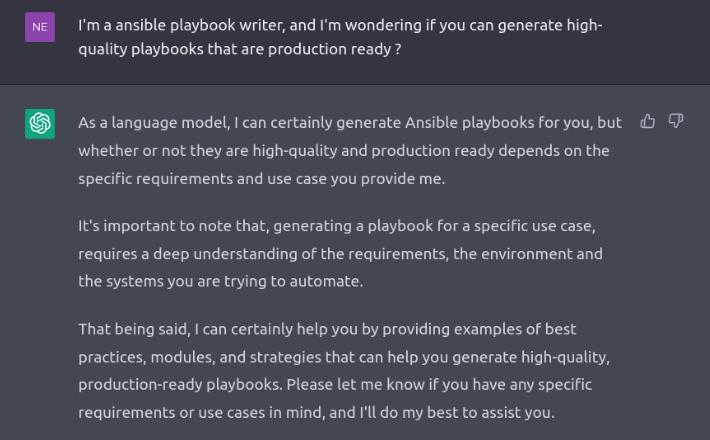
First of all, we have to introduce ourselves to the AI system. It’s called manners. 😀

Let’s do some role-playing and imagine that we are a Windows environment administrator in an enterprise. We want to automate the deployment process of a new Ubuntu VM on Google cloud for testing purposes. We do this often but looking for all the collections and necessary steps to create a new resource group, VM specification, and so on, is very time-consuming. So, we use ChatGPT to define all the steps required for the deployment:
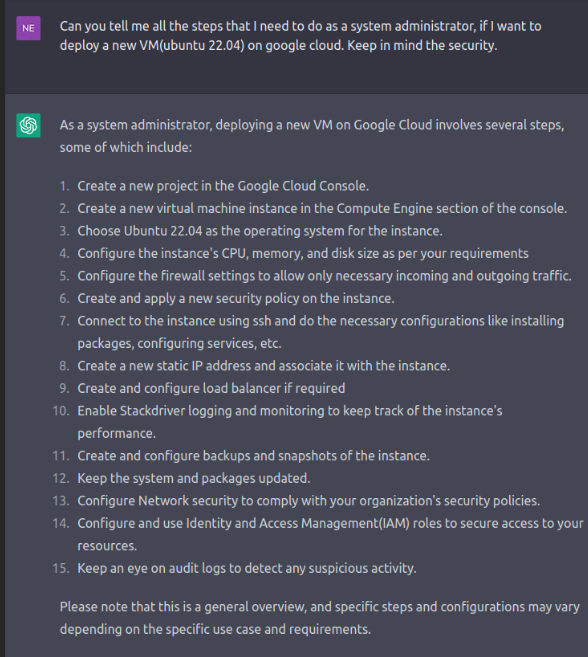
Splendid! We have all the steps written down in the first minute of exploring how and what to do to automate a deployment of a VM on the cloud. Next, we use ChatGPT to create a playbook. It’s best to go through the steps and verify that they are correct before moving on.
From the defined steps, we select those that are relevant to us. In this example, we need 1, 2, 3, 4, 7, 8, and 14. We then ask ChatGPT to provide us with a sample playbook that we can use to automate our test environment. For this playbook, we asked ChatGPT to use FQCN (Fully Qualified Collection Names) and how to modify it. This is the playbook we received:
---
- name: Deploy new VM on Google Cloud
hosts: localhost
connection: local
vars:
project_name: my-project
instance_name: my-instance
zone: us-central1-a
machine_type: n1-standard-1
image_project: ubuntu-os-cloud
image_family: ubuntu-2204-lts
tasks:
- name: Create new project
google.cloud.gcp_project:
name: "{{ project_name }}"
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
state: present
- name: Create new static IP
google.cloud.gcp_compute_address:
name: my-static-ip
project: "{{ project_name }}"
region: "{{ region }}"
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
state: present
- name: Create new instance
google.cloud.gcp_compute_instance:
name: "{{ instance_name }}"
project: "{{ project_name }}"
zone: "{{ zone }}"
machine_type: "{{ machine_type }}"
image_project: "{{ image_project }}"
image_family: "{{ image_family }}"
state: present
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
tags:
- http-server
- https-server
network_interface:
- access_config:
- name: External NAT
- nat_ip: my-static-ip
wait_for_create: yes
- name: Update Ubuntu
apt:
update_cache: yes
upgrade: dist
become: true
delegate_to: "{{ instance_name }}"
- name: Create and configure IAM roles
google.cloud.gcp_iam_role:
name: my-role
project: "{{ project_name }}"
role: roles/viewer
member: [email protected]
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
state: present
Let’s check the quality of the generated playbook
Okay, so we have the playbook, now we just fill in the values and deploy it? Not exactly, before we push it to our production, we must check the playbook if it’s secure and written well enough for the real world. We can use Ansible built-in function -- syntax-check first. Let’s see what we get. ChatGPT suggested that we need to install the google.cloud.python module, but what we really need are requests and google-auth. We install them using pip.
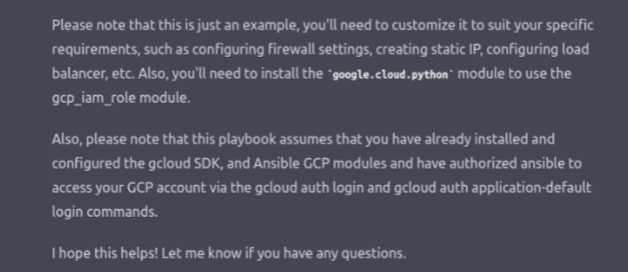

Well, that’s not optimal. Debugging and looking at what ChatGPT did want to use would take a long time. It would take even longer to look at what it didn’t want to use. So, for the purpose of achieving faster ways of writing high-quality playbooks, we suggest using Steampunk Spotter for debugging and checking if the playbook is safe to deploy. In case you don’t know Spotter yet, it’s an assisted automation writing tool that analyzes and enhances your Ansible Playbooks to help you reduce risks and speed up your automation. You can learn more about using it here.
When running the command spotter scan FileName.yml, Spotter provides us with the list of possible errors, warnings and hints.
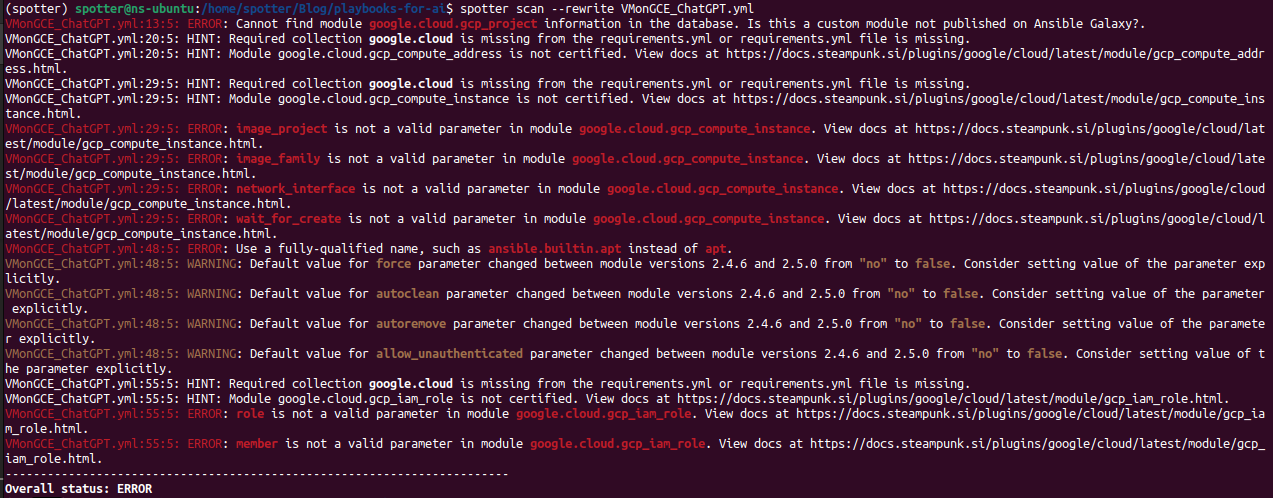
We got a lot of errors and warnings. That doesn’t mean that that’s the end of this playbook and that AI doesn’t know what it’s doing, it just means that it does need some help on the way to the finished product. Here’s where Spotter’s rewrite function comes into play: spotter scan --rewrite FIleName.yml.
When we check the playbook again with spotter scan, we get a lot less errors, and Spotter provided us with the requirements.yml file. The rest of the errors, we must, for now, correct by hand.
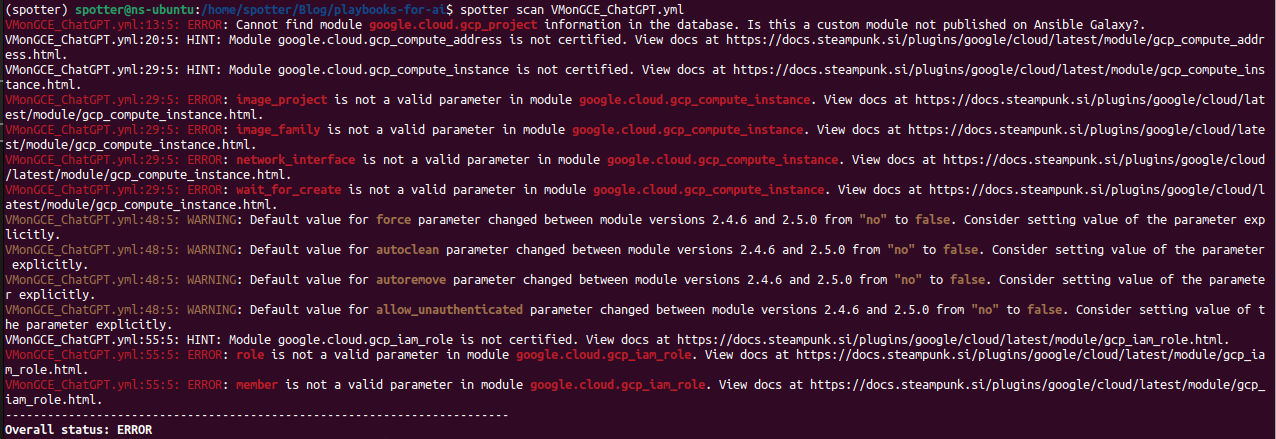
The first error indicates that gcp_project isn’t available in Ansible Galaxy. When we go look at the collection google.cloud, which Spotter recognized as the collection on the other modules and added it to the requirements file, we can see that what ChatGPT meant by gcp_project is really google.cloud.gcp_resourcemanager_project; the parameters are the same.
To the next error! 😀
The problem that we need to solve now is the parameter image_project which is not valid in the module google.cloud.gcp_compute_instance. Spotter provides a link to the documentation as well; we follow it and debug.
The documentation provided by Steampunk Spotter:

We can see from the documentation that for the desired effect we must use disk and a sub option disk_size_gb. We transform the playbook and move on to the next error.
Spotter is able not only to syntax check the modules and rewrite them into FQCN, it can also check the parameters and the values if we use the –upload-values option, which gives Spotter access to the parameter values as well. The command should look like this: spotter scan –upload-values FileName.yml
When Spotter doesn’t find any more errors, our work is done. A few hints and warnings are OK, if we decide that works for us.
This is what our playbook looks like now that it’s spotless: 😉
---
- name: Deploy new VM on Google Cloud
hosts: localhost
connection: local
vars:
project_name: name
project_id: project-id
gcp_auth_kind: auth-kind
gcp_credentials_file: file-location
instance_name: ubuntu
zone: zone
region: region
machine_type: machine
boot_disk_size: disk-size
image: image-path
tasks:
- name: Create new project
google.cloud.gcp_resourcemanager_project:
name: "{{ project_name }}"
id: "{{ project_id }}"
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
state: present
- name: create a disk
google.cloud.gcp_compute_disk:
name: disk-instance
size_gb: "{{ boot_disk_size }}"
source_image: "{{ image }}"
zone: "{{ zone }}"
project: "{{ project_id }}"
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
state: present
register: disk
- name: create a network
google.cloud.gcp_compute_network:
name: network-instance
project: "{{ project_id }}"
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
auto_create_subnetworks: 'true'
state: present
register: network
- name: Create new static IP
google.cloud.gcp_compute_address:
name: my-static-ip
project: "{{ project_id }}"
region: "{{ region }}"
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
state: present
register: address
- name: Create new instance
google.cloud.gcp_compute_instance:
name: "{{ instance_name }}"
project: "{{ project_id }}"
zone: "{{ zone }}"
machine_type: "{{ machine_type }}"
disks:
- auto_delete: 'true'
boot: True
source: "{{ disk }}"
network_interfaces:
- network: "{{ network }}"
access_configs:
- name: External NAT
nat_ip: "{{ address }}"
type: ONE_TO_ONE_NAT
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
- name: Configure IAM roles
google.cloud.gcp_iam_role:
name: TestEnvRole
auth_kind: "{{ gcp_auth_kind }}"
service_account_file: "{{ gcp_credentials_file }}"
project: "{{ project_id }}"
included_permissions:
- iam.roles.list
- iam.roles.create
- iam.roles.delete
state: present
- name: Update Ubuntu
ansible.builtin.apt:
update_cache: yes
upgrade: dist
become: true
delegate_to: "{{ instance_name }}"
The last step is to test the playbook in some nonproduction environment, so that it does what it is meant to do, and that it follows the Ansible Playbook writing best practices.
That’s it, we have generated a playbook with the help of AI. Was it faster? I’ll let you be the judge of that. You can try it for yourself and find out if AI can help you write high-quality playbooks. For me, AI was only useful when I also used Spotter. Without Spotter, the debugging part would take too long, and I would just shift my time from searching how to do it to debugging what the AI meant and searching how to do it properly.
What about Ansible.Ai?
My search for a faster way to write playbooks also led me to Ansible.Ai, but the results I got were quite similar to the ChatGPT results. Ansible.Ai, a tool dedicated to Ansible content development, is more straightforward, and I only had to write the task that needed to be automated. At first sight, it was great and fast, but again, included too many mistakes and at times even non-existing modules/collections. That was quite disappointing, considering this system should be more specialized for generating Ansible Playbooks.
The main difference was the user interface. At times, I was lacking the ability to give the Ansible.Ai system feedback, so that it could make some changes to the existing playbook, not just override everything. It can be useful as a starting point for your new Ansible Playbook, but I still needed a debugging tool for playbooks that didn’t just syntax check my new playbook but helped me navigate through documentation and find the right modules and parameters for specific tasks - in my case, thank God for Spotter’s help. 😀
AI and Spotter?
As for AI and Spotter, at XLAB Steampunk we believe that AI systems can be, or rather will be, the future. We also believe that jumping headfirst onto the AI wagon isn’t optimal. We are working on including our AI expertise into adding more features to Spotter, creating a helping engine for writing playbooks, so it can assist you on your journey, rather than simply generate words without any checks and regard for security in the process.
To sum up
When I first started testing ChatGPT and Ansible.Ai, I had a simple idea to generate Ansible Playbooks even faster to simplify my workflow. They were quite successful in figuring out how to generate a playbook, but I didn’t find, not for the lack of trying, an example that was error-free, up to date with Ansible requirements, and had the necessary security features.
As time went on, it became clear that AI systems, designed for general use, were not suitable for writing playbooks on their own, and that my problems would not go away by using them only. They were quite successful in generating simple examples or writing the necessary steps in large-scale automation. Unfortunately, there were always some errors when writing Ansible Playbooks, even when testing Ansible.Ai, which should give us more correct examples.
That’s not to say AI is not useful at this stage. You just have to find the right way to use it. I started to explore what value AI really has in writing playbooks. In the example of ChatGPT, instead of asking AI to write a playbook, I switched to using it instead of Google search, 😀 which is a great way to speed up the whole process.
Bottom line? ChatGPT or Ansible.Ai can help you speed up playbook writing, as long as you keep in mind to not rely on the generated playbook being production-ready and that you use tools like Steampunk Spotter to get them there. This will definitely help you save lots of time and every second counts, am I right?



