This post was originally published on the
XLAB Steampunk blog.
Ansible Collections gave us much more control over the content we use when building our Ansible Playbooks. But they also brought on a new challenge: identifying high-quality content. Take a look here to see how to make sure the content you intend to use in your playbooks is up to standard.
And that’s only the first step. After finding high-quality collections, Ansible Playbook authors still need to use that content appropriately to write a reliable playbook. See which guidelines you should follow to improve the quality of your automation.
So, identifying quality content and then taking the right steps for writing reliable playbooks should do the trick, right? Well, as it usually is, things aren’t that simple. Following all the guidelines still doesn’t guarantee things won’t break. Luckily, we have some experience with writing playbooks and, inevitably, making mistakes, so we’re sharing some tips to save you from repeating them.
In this blog post, we’ll show you how to gradually build a sustainable development workflow that you can use as the base of your development setup to make your playbooks reliable and make you trust your automation more. We’ll also point out the tools that can help you catch potential errors before the breaking ruins your day.

We will start small and simple: with just Ansible and our playbook.
Run early, run often
You probably already heard about the “run early, run often” rule in some non-Ansible context, but it also applies in the Ansible world. When writing Ansible Playbooks, we highly suggest running them after each task you add. Why? Because when we mess things up, Ansible lets us know that right away. And since Ansible errors can get quite lengthy and dense, having a single source of bugs is a must.
Once all you can see are OK and changed statuses in the Ansible output, you can be sure your newly added playbook task does not have typos and other obvious errors.
It is true that once things grow a bit bigger, playbook executions start to take longer and longer, but here’s an idea: see this as an opportunity to optimize your playbook. For example, making sure you do not download things repeatedly if you don’t have to can massively improve runtimes. And future us will be glad we did this.
Run it again
You might be thinking we’ve lost it, suggesting running paybooks twice in a row, but hear us out. The idea of this second run is to make sure Ansible changes nothing when rerunning the playbook. Why is this important? Because it forces us to think about the desired state of the target system. Ansible Playbooks that enforce a particular state are way more versatile and robust compared to their action-executing counterparts.
For example, we can just rerun the whole playbook if one task fails because of intermittent
network problems. But if our playbook is executing state-unaware actions, we would most probably need to
comment out already-executed parts of the playbook to avoid making things even worse. Or use the
--start-at-task Ansible command-line switch, which is not much better.
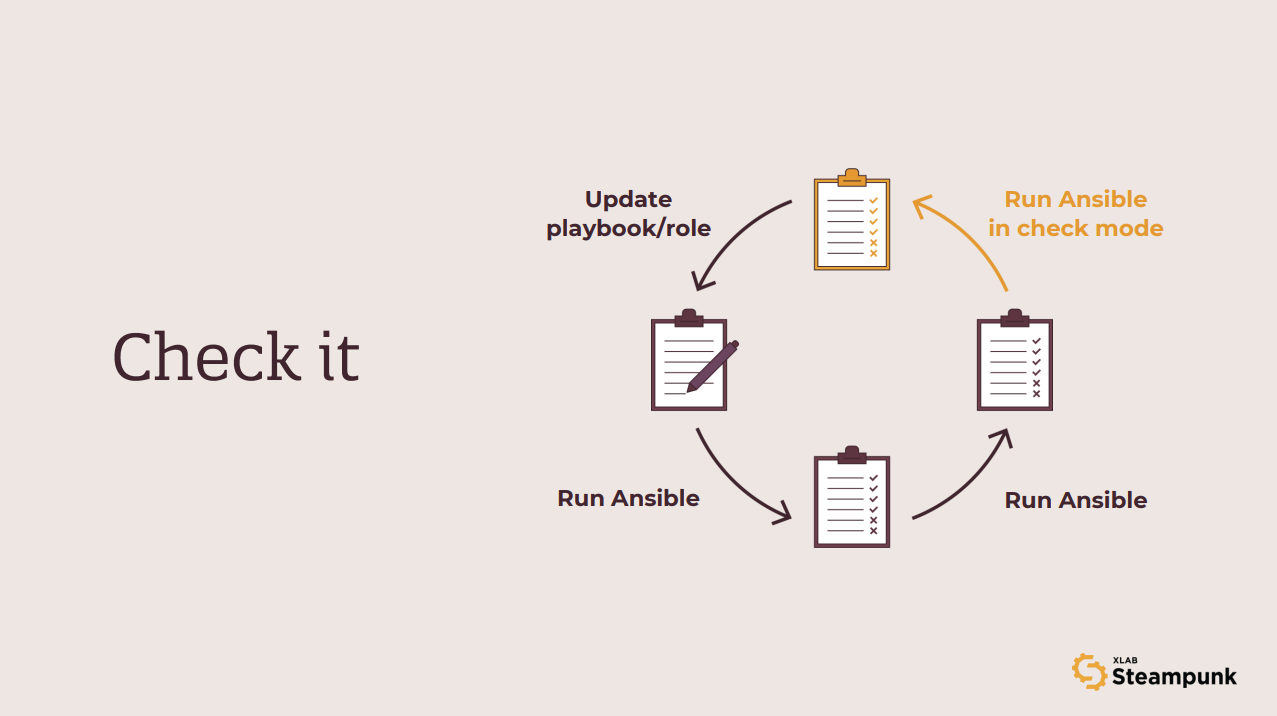
Check it
So, what is next? Well, to run Ansible once again, of course! But this time, we will spice things up a bit and run Ansible in check mode. And we swear that this is the last Ansible run we will add to the workflow. The main idea behind this new run is to make sure no tasks fail in check mode. Why? Because this opens a lot of new opportunities for playbook reuse. For example, we can run such playbooks in check mode once per day, and if any of the runs report back a changed task, we know someone or something was messing with our system.
This configuration drift detection mechanism performs exceptionally well if the modules we use
support diff mode. In that case, we can actually see the changes that were made.
Use ansible-playbook --check --diff to use this feature.
Starting over is hard
One thing we have ignored so far is the host that we run our playbooks and roles against. We assumed that the host was always available and would tolerate all the abuse from our playbooks. But of course, this is not what happens in reality. It takes just one poorly constructed task to make the test host unusable.
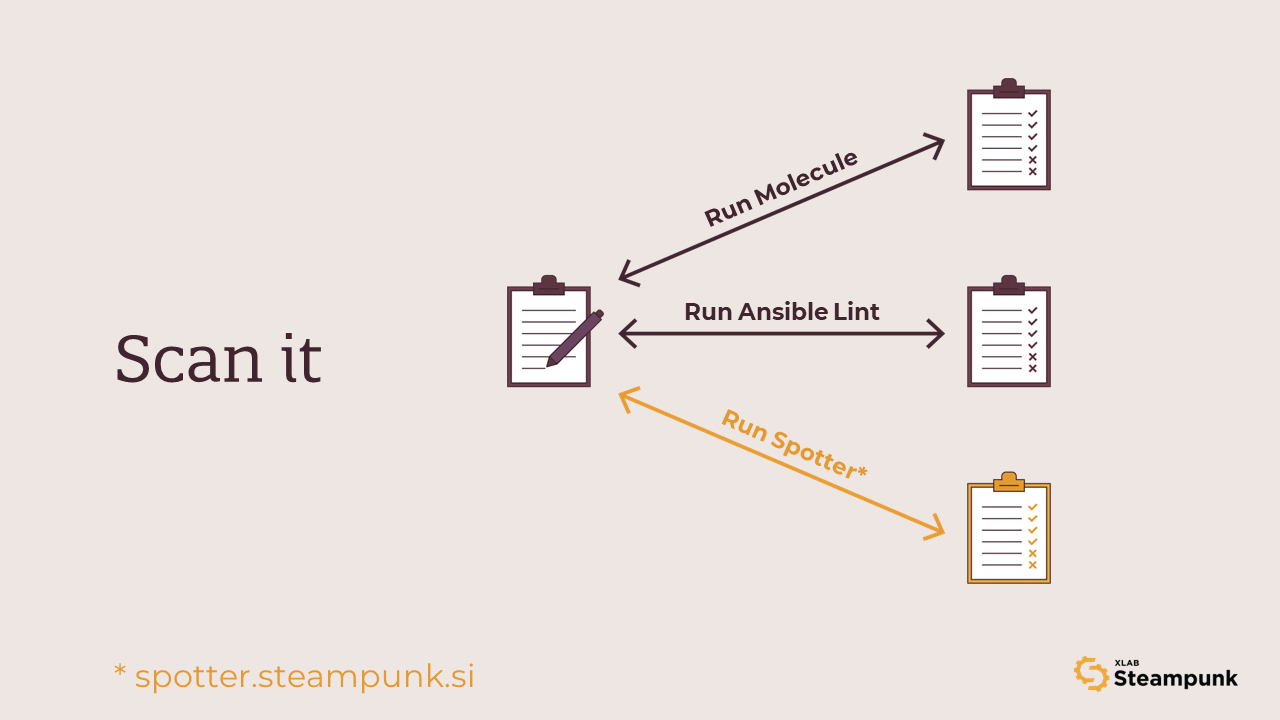
And while recreating a VM or a container from time to time is not too big of a deal, it has the potential to become a significant time sink once we start expanding our testing efforts. For example, if our playbook or role is expected to work on three different operating systems, we must suddenly maintain three separate hosts to test against. And host lifecycle management is what Molecule knows how to do best.
Once we describe our test environment, we can use Molecule to create test hosts, run our playbooks and roles on created hosts, and destroy the hosts once the test run is over. Find out how to write tests that won’t slow you down here!
But we don’t have to always execute all steps. In fact, Molecule is smart enough to skip some of the steps if they are not needed. For example, if we run the converge command twice in a row, only the first execution will create new hosts. The second converge run will reuse the existing hosts if they still exist.
Following the steps above assures our automation will perform reliably. But there is nothing in our workflow that would help us adopt best practices that crystalized in the Ansible community over the years. And this is what we will tackle next.
Linting
Ansible Lint is, at its core, a collection of rules that playbooks should follow. And yes, some rules are made to be broken. For example, Ansible Lint will warn you if your Jinja expressions do not have spaces before and after, and if you feel having things styled your own way, you can always ignore such warnings. Though even if stylistic deviations do not make a difference in the playbook’s functionality, having a consistent style in the codebase never hurts.
But there are other rules that we should never ever ignore. The risky file permissions warning is one such example that reminds us that we should pay attention to security when using modules like copy or template.
And this is it. We did all we could, our playbooks and roles are flawless, and Padme is happy. Right? Well … you’ve might have guessed it; things still aren’t that simple. Even all the running and rerunning and checking doesn’t guarantee catching all potential errors. But don’t be discouraged, as said, we’re here to help.
Scan it
Because we know how frustrating it can be to follow all the procedures, guidelines, and still end up with a playbook that just won’t do what you want it to do, we developed our Steampunk Spotter, an assisted automation writing tool that analyzes and offers recommendations for your Ansible Playbooks to help you reduce risks and speed up your automation. Unlike other similar tools, Spotter goes beyond simple syntax checks and understands the context of Ansible Playbooks and Ansible Collections, which means it knows what you want to achieve and helps you get there faster and safer.
With Spotter, you can structure your playbooks for readability, collaboration and ease of use, check for fully qualified names, ensure you are using certified modules, quickly identify invalid configurations, and more. Go ahead, start Spotting!
CI
So, this brings us to the last topic: continuous integration. Great news: the workflow we built works just great in CI environments. All the mentioned tools have a command-line interface and can run on GitHub Actions, CircleCI, Azure Pipelines, etc. All we have to do is write down a configuration file for our favorite CI provider and wait for those sweet green OKs on our pull requests.
Takeaway
So what did we learn today? Well, first, to err is human. Secondly, that there are some tools out there that have our back and can make our playbooks and roles much more reliable and robust. And finally, we learned that once we have our workflow set up, we can easily reuse it in the continuous integration settings.
But most importantly, we wanted to share this piece of advice. Actively search for things that can break. Embrace the tools that will yell at you. Those tools were created by people who were burned by that error. Learn from mistakes other people made before you.
Want to know more about making and avoiding mistakes in your Ansible Playbooks? Hear it straight from the man who admits messing things up a lot in this short webinar. More interested in just the avoiding part? Try out our Steampunk Spotter to shape up your playbooks much more gracefully 😉